
Мы продолжаем публиковать разборы задач, которые предлагались на недавнем чемпионате. На очереди — задачи, взятые из квалификационного раунда для специалистов по машинному обучению. Это третий трек из четырёх (бэкенд, фронтенд, ML, аналитика). Участникам нужно было сделать модель исправления опечаток в текстах, предложить стратегию игры на игровых автоматах, довести до ума систему рекомендаций контента и составить ещё несколько программ.
A. Опечатки
Условие
(эпиграф)(с одного форума)
— Кто сочинил эту чушь?
— Астрофизики. Они тоже люди.
— Вы 10 ошибок в слове «журналисты» сделали.
Многие пользователи делают ошибки при наборе, некоторые — из-за попаданий мимо клавиш, некоторые — из-за своей неграмотности. Мы хотим проверить, мог ли пользователь на самом деле иметь в виду некоторое другое слово, чем то, которое он набрал.
Более формально, предположим, что имеет место следующая модель ошибок: пользователь начинает с некоторого слова, которое он хочет написать, и дальше последовательно делает в нём некоторое количество ошибок. Каждая ошибка представляет собой замену некоторой подстроки слова на другую подстроку. Одна ошибка соответствует замене только в одной позиции (то есть если пользователь захочет сделать единственную ошибку по правилу «abc»→«cba», то из строки «abcabc» он может получить либо «cbaabc», либо «abccba»). После каждой ошибки процесс повторяется. Одно и то же правило могло использоваться несколько раз в различных шагах (так, в вышеприведённом примере за два шага могло получиться «cbacba»).
Требуется определить, какое минимальное количество ошибок пользователь мог совершить, если он имел в виду одно заданное слово, а написал другое.
Форматы ввода/вывода и примерФормат ввода
В первой строке содержится слово, которое, по нашему предположению, пользователь имел в виду (оно состоит из букв латинского алфавита в нижнем регистре, длина не превышает 20).
Во второй строке содержится слово, которое он на самом деле написал (оно также состоит из букв латинского алфавита в нижнем регистре, длина не превышает 20).
В третьей строке содержится единственное число N (N < 50) — количество замен, описывающих различные ошибки.
В следующих N строках содержатся возможные замены в формате <«правильная» последовательность букв><пробел><«ошибочная» последовательность букв>. Последовательности имеют длину не более 6 символов.
Формат вывода
Требуется вывести одно число — минимальное количество ошибок, которое мог совершить пользователь. Если это количество превышает 4 или же из одного слова невозможно получить другое, следует вывести –1.
Пример
Решение
Попробуем сгенерировать из правильного написания все возможные слова не более чем с 4 ошибками. Их в худшем случае может быть O((L﹒N)
4). В ограничениях задачи это довольно большое число, поэтому нужно придумать, как уменьшить сложность. Можно вместо этого воспользоваться алгоритмом meet-in-the-middle: сгенерировать слова не более чем c 2 ошибками, а также слова, из которых можно получить написанное пользователем слово, сделав не более 2 ошибок. Заметим, что размер каждого из этих множеств не будет превышать 10
6. Если количество сделанных пользователем ошибок не превосходит 4, то эти множества будут пересекаться. Аналогично можно проверить, что число ошибок не превосходит 3, 2 и 1.
B. Многорукий бандит
Условие
Это интерактивная задача.
Вы сами не знаете как так вышло, но вы обнаружили себя в зале с игровыми автоматами с целым мешком жетонов. К сожалению, в кассе жетоны назад принимать отказываются, и вы решили испытать свою удачу. В зале есть много автоматов, в которые вы можете играть. Для одной игры с автоматом вы используете один жетон. В случае выигрыша автомат даёт вам один доллар, в случае проигрыша — ничего. У каждого автомата есть фиксированная вероятность выигрыша (которую вы не знаете), но у разных автоматов она разная. Изучив сайт производителя этих автоматов, вы выяснили, что вероятность выигрыша у каждого автомата выбирается случайно на этапе изготовления из бета-распределенияс определёнными параметрами.
Вам хочется максимизировать свой ожидаемый выигрыш.
Форматы ввода/вывода и примерФормат ввода
Одно исполнение может состоять из нескольких тестов.
Каждый тест начинается с того, что вашей программе в одной строке подаются два целых числа, разделённые пробелом: число N — количество жетонов в вашем мешке, и M — количество автоматов в зале (N ≤ 104, M ≤ min(N, 100)). В следующей строке содержатся два вещественных числа α и β (1 ≤ α, β ≤ 10) — параметры бета-распределения вероятности выигрыша.
Протокол общения с проверяющей системой такой: вы делаете ровно N запросов. На каждый запрос выведите в отдельную строку номер автомата, в который вы будете играть (от 1 до M включительно). В качестве ответа в отдельной строке будет стоять либо «0», либо «1», означающие соответственно проигрыш и выигрыш в игре с запрошенным автоматом.
После последнего теста вместо чисел N и M будут стоять два нуля.
Формат вывода
Задача будет считаться сданной, если ваше решение не сильно хуже решения жюри. Если ваше решение будет значительно хуже решения жюри, вы получите вердикт «неправильный ответ».
Гарантируется, что если ваше решение не хуже, чем решение жюри, то вероятность получить вердикт «неправильный ответ» не превосходит 10–6.
Примечания
Пример взаимодействия:
Решение
Эта задача достаточно известна, её можно было решать по-разному. Основное решение жюри реализовывало стратегию Thompson sampling, но поскольку число шагов было известно в начале работы программы, существуют и более оптимальные стратегии (например, UCB1). Более того, можно было даже обойтись epsilon-greedy-стратегией: с некоторой вероятностью ε играть в случайный автомат и с вероятностью (1 – ε) играть в автомат, у которого статистика побед лучше всего.
C. Выравнивание предложений
Условие
Одна из важнейших задач для обучения хорошей модели машинного перевода — хороший корпус параллельных предложений. Обычно источником для параллельных предложений являются параллельные документы. Оказывается, часто для того, чтобы построить некоторый корпус параллельных предложений, не нужно знать ничего, кроме их длин. В частности, можно заметить, что чем длинее предложение на исходном языке, тем длинее, скорее всего, будет его перевод. Некоторая сложность состоит в том, что при переводе количество предложений в тексте может поменяться: иногда два соседних предложения при переводе могут быть объединены в одно, или наоборот — одно предложение могло быть разделено на два. В отдельных редких случаях предложения могут целиком пропускаться в переводе, или в переводе может появиться предложение, которого не было в оригинале.
Более формально, предположим, что верна следующая генеративная модель для параллельных корпусов. На каждом шаге мы совершаем одно из следующих действий:
1. ОстановкаС вероятностью p
hгенерация корпусов заканчивается.
2. [1-0] Пропуск предложенияС вероятностью p
dприписываем в оригинальный текст одно предложение. В перевод не приписываем ничего. Длина предложения на языке оригинала L ≥ 1 выбирается из дискретного распределения:
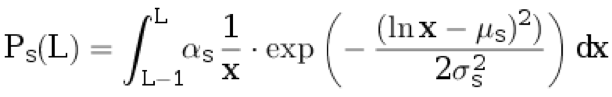
.
Здесь
μs,
σs— параметры распределения, а
αs— нормировочный коэффициент, выбираемый так, чтобы

.
3. [0-1] Вставка предложенияС вероятностью p
iприписываем в перевод одно предложение. В оригинал не приписываем ничего. Длина предложения на языке перевода L ≥ 1 выбирается из дискретного распределения:

.
Здесь
μt,
σt— параметры распределения, а
αt— нормировочный коэффициент, выбираемый так, чтобы

.
4. ПереводС вероятностью (1 – p
d– p
i– p
h) берём длину предложения на языке оригинала L
s≥ 1 из распределения p
s(с округлением вверх). Далее генерируем длину предложения на языке перевода L
t≥ 1 из условного дискретного распределения:
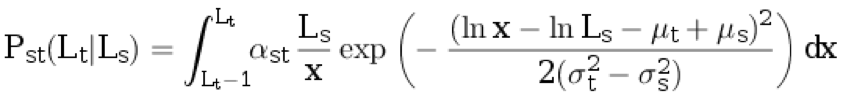
.
Здесь
αst— нормировочный коэффициент, а остальные параметры описаны в предыдущих пунктах.
Далее происходит ещё один шаг:
1. [2-1] С вероятностью p
split sсгенерированное предложение на языке оригинала распадается на два непустых, так, чтобы суммарное количество слов
увеличилось ровно на один. Вероятность того, что предложение длины L
sраспадётся на части длиной L
1и L
2(то есть L
1+ L
2= L
s+ 1), пропорциональна P
s(L
1) ⋅ P
s(L
2).
2. [1-2] С вероятностью p
split tсгенерированное предложение на языке перевода распадается на два непустых, так, чтобы суммарное количество слов увеличилось ровно на один. Вероятность того, что предложение длины L
tраспадётся на части длиной L1 и L2 (то есть L
1+ L
2= L
t+ 1), пропорциональна P
t(L
1) ⋅ P
t(L
2).
3. 3. [1-1] С вероятностью (1 – p
split s– p
split t) ни одно из пары сгенерированных предложений не распадётся.
Форматы ввода/вывода, примеры и примечанияФормат ввода
В первой строке файла записаны параметры распределений: p
h, p
d, p
i, p
split s, p
split t, μ
s, σ
s, μ
t, σ
t. 0,1 ≤ σ
s< σ
t≤ 3. 0 ≤ μ
s, μ
t≤ 5.
В следующей строке стоят числа N
sи N
t— количество предложений в корпусе на языке оригинала и на языке перевода соответственно (1 ≤ N
s, N
t≤ 1000).
В следующей строке находятся N
sцелых чисел — длины предложений на языке оригинала. В следующей строке находятся N
tцелых чисел — длины предложений на языке перевода.
В следующей строке находятся два числа: j и k (1 ≤ j ≤ N
s, 1 ≤ k ≤ N
t).
Формат вывода
Требуется вывести вероятность того, что предложения с индексами j и k в текстах соответственно являются параллельными (то есть что они сгенерированы на одном шаге алгоритма и ни одно из них не является результатом распада).
Ваш ответ будет принят, если абсолютная погрешность не превосходит 10
–4.
Пример 1
Пример 2
Пример 3
Примечания
В первом примере исходную последовательность чисел можно получить тремя способами:
• Сначала с вероятностью p
dдописать одно предложение в оригинальный текст, затем с вероятностью p
iдописать одно предложение в перевод, потом с вероятностью p
hзакончить генерацию.
Вероятность этого события равна P
1= p
d* P
s(4) * p
i* P
t(20) * p
h.
• Сначала с вероятностью p
dдописать одно предложение в оригинальный текст, затем с вероятностью p
iдописать одно предложение в перевод, потом с вероятностью p
hзакончить генерацию.
Вероятность этого события равна P
2= p
i* P
t(20) * p
d* P
s(4) * p
h.
• C вероятностью (1 – p
h– p
d– p
i) сгенерировать два предложения, затем с вероятностью (1 – p
split s– p
split t) оставить всё как есть (то есть не разбивать на два предложения ни оригинал, ни перевод) и после этого с вероятностью p
hзакончить генерацию.
Вероятность этого события равна

.
В итоге ответ рассчитывается как

.
Решение
Задача является частным случаем выравнивания с помощью скрытых марковских моделей (HMM alignment). Основная идея состоит в том, что можно вычислить вероятность генерации конкретной пары документов с помощью этой модели и алгоритма forward: в данном случае состоянием является пара префиксов документов. Соответственно, требуемую вероятность выравнивания конкретной пары параллельных предложений можно вычислить алгоритмом forward-backward.
Код
D. Лента рекомендаций
Условие
Рассмотрим ленту рекомендаций разнородного контента. В ней смешаны объекты разного типа (картинки, видео, новости и т. д.). Эти объекты обычно упорядочиваются по релевантности пользователю: чем релевантнее (интереснее) объект пользователю, тем он ближе к началу списка рекомендаций. Однако при таком упорядочивании часто возникают ситуации, в которых в списке рекомендаций встречаются несколько объектов подряд одного типа. Это сильно ухудшает внешнее разнообразие наших рекомендаций и поэтому не нравится пользователям. Необходимо реализовать алгоритм, который по списку рекомендаций составит новый список, который будет лишен этой проблемы и будет наиболее релевантным.
Пусть задан исходный список рекомендаций a = [a
0, a
1,…, a
n − 1] длины n > 0. Объект под номером i имеет тип с номером b
i∈ {0,…, m − 1}. Кроме того, объект под номер i имеет релевантность r(a
i) = 2
−i. Рассмотрим список, который получается из исходного выбором подмножества объектов и их перестановкой: x = [a
i0, a
i1,…,a
ik−1] длины k (0 ≤ k ≤ n). Список называется допустимым, если никакие два подряд идущих объекта в нём не совпадают по типу, т. е. b
ij≠ b
ij + 1для всех j = 0,…, k−2. Релевантность списка вычисляется по формуле

. Вам нужно найти максимальный по релевантности список среди всех допустимых.
Форматы ввода/вывода и примерыФормат ввода
На первой строке через пробел записаны числа n и m (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). На следующих n строках записаны числа biдля i = 0,…, n − 1 (0 ≤ bi≤ m − 1).
Формат вывода
Выпишите через пробел номера объектов итогового списка: i0, i1,…, ik−1.
Пример 1
Пример 2
Пример 3
Решение
Путем несложных математических выкладок можно показать, что задача может быть решена «жадным» подходом, т. е. в оптимальном списке рекомендаций на каждой позиции стоит самый релевантный объект из всех, которые допустимы при том же начале списка. Имплементация этого подхода простая: берём объекты подряд и добавляем их в ответ, если это возможно. Когда встречается недопустимый объект (тип которого совпадает с типом предыдущего), то откладываем его в отдельную очередь, из которой вставляем в ответ при первой же возможности. Заметим, что в каждый момент времени у всех объектов в этой очереди будет совпадающий тип. В конце в очереди могут остаться несколько объектов, они уже не войдут в ответ.
D. Кластеризация символьных последовательностей
Имеется конечный алфавит A = {a
1, a
2,…, a
K−1, a
K= S}, a
i∈ {a, b,…, z}, S — конец строки.
Рассмотрим следующий способ генерации случайных строк над алфавитом A:
1. Первый символ x
1— случайная величина с распределением P(x
1= a
i) = q
i(известно, что q
K= 0).
2. Каждый следующий символ генерируется на основе предыдущего в соответствии с условным распределением P(x
i= a
j
nest...
39274 39275 39276 39277 39278

